| |||||||||
|


Accept() scalability on Linux
Steve Molloy, CITI - University of Michiganlinux-scalability@citi.umich.edu
Abstract |
|---|
|
This report explores the possible effects of a "thundering herd" problem associated with the Linux implementation of the POSIX accept() system call. We discuss the nature of the problem and how it may affect the scalability of the Linux kernel. In addition, we identify candidate solutions and considerations to keep in mind. Finally, we present a solution and benchmark it, giving a description of the benchmark methodology and the results of the benchmark. |
Introduction
Network servers that use TCP/IP to communicate with their clients are rapidly increasing their offered loads. A service may elect to create multiple threads or processes to wait for increasing numbers of concurrent incoming connections. By pre-creating these multiple threads, a network server can handle connections and requests at a faster rate than with a single thread.
In Linux, when multiple threads call accept() on the same TCP socket, they get put on the same wait queue, waiting for an incoming connection to wake them up. In the Linux 2.2.9 kernel (and earlier), when an incoming TCP connection is accepted, the wake_up_interruptible() function is invoked to awaken waiting threads. This function walks the socket's wait queue and awakens everybody. All but one of the threads, however, will put themselves back on the wait queue to wait for the next connection. This unnecessary awakening is commonly referred to as a "thundering herd" problem and creates scalability problems for network server applications.
This report explores the effects of the "thundering herd" problem associated with the accept() system call as implemented in the Linux kernel. In the rest of this paper, we discuss the nature of the problem and how it affects the scalability of network server applications running on Linux. Finally, we will benchmark the solutions and give the results and description of the benchmark. All benchmarks and patches are against the Linux 2.2.9 kernel.
Investigation
While researching the TCP/IP accept code, we found a few interesting points. The socket structure in Linux contains a virtual operations vector, similar to VFS inodes, that lists six methods (referred to as call-backs in some kernel comments). These methods are initially pointed to a set of generic functions for all sockets when each socket is created. Each socket protocol family (e.g., TCP) has the option to override these default functions and point the method to a function specific to the protocol family. TCP overrides just one of these methods for TCP sockets. The four most commonly-used socket methods for TCP sockets are as follows:
sock->state_change.................... (pointer to sock_def_wakeup)
sock->data_ready...................... (pointer to sock_def_readable)
sock->write_space..................... (pointer to tcp_write_space)
sock->error_report.................... (pointer to sock_def_error_report)
The code for each one of these methods invokes the wake_up_interruptible() function. This means that every time one of these methods is called, tasks may be unnecessarily awakened. In fact, in the accept() call alone, Linux invokes three of these methods, essentially tripling impact of the "thundering herd" problem. The three methods invoked in every call to accept() in the 2.2.9 kernel are tcp_write_space(), sock_def_readable() and sock_def_wakeup(), in that order.
Because the most frequently used socket methods call wake_up_interruptible(), the thundering herd problem extends beyond the accept() system call and into the rest of the TCP code. In fact, it is rarely necessary for these methods to wake up the entire wait queue. Thus, almost any TCP socket operation unnecessarily awakens tasks and returns them to sleep. This inefficient practice robs valuable CPU cycles from server applications.
Guidelines
When developing solutions to any problem, it its important to establish a few rules to warrant acceptability and quality. While investigating the Linux TCP code, we set forth this particular set of guidelines to ensure the correctness and quality of our solution:
- Don't break any existing system calls
If the changes affect the behavior of any other system calls in an unexpected way, then the solution is unacceptable. - Preserve "wake everybody" behavior for calls that rely on it
Some calls may rely on the "wake everybody" behavior of wake_up_interruptible(). Without this behavior, they may not conform to POSIX specifications. - Make solution as simple as possible without adding too much new code in too many places
The more complicated the solution, the more likely it is to break something or have bugs. Also, we want to try to keep the changes as local to the TCP code as possible so other parts of the kernel don't have to worry about tripping over the changed behavior. - Try not to change any familiar/expected interfaces unless absolutely necessary
It would not be a good idea to require an extra flag to an existing function call. Not only would every use of that function have to be changed, but programmers who are used to its interface would have to learn to supply an extra argument. - Make the solution general, so it can be used by the entire kernel
If any other parts of the kernel are experiencing a similar "thundering herd" problem, it may be easily fixed with this same solution instead of having to create a custom solution in another section of the kernel.
Solutions
One proposed solution to this problem was suggested by the Linux community after the accept() "thundering herd" problem was brought to their attention. The idea is to add a flag in the kernel's task structure and change the handling of wait queues in the __wake_up() and add_wait_queue_exclusive() functions. A bit in the state variable of the task structure is reserved for a "exclusive" marking and the accept() system call would be responsible for setting this "exclusive" flag and adding the task to the wait queue.
In handling the wait queue, __wake_up() will walk the wait queue, waking tasks as it goes until it runs into its first "exclusive" task. It will wake this task and then exit, leaving the rest of the queue waiting. To ensure that all tasks that are not marked exclusive were awakened, add_wait_queue() will be complemented by add_wait_queue_exclusive() which will add an exclusive task to the end of the wait queue, after all non-exclusive waiters, to ensure that all "normal" tasks are walked through first. Programmers would be responsible for ensuring that all exclusive tasks are added to the wait queue with add_wait_queue_exclusive().
Another solution, stemming from the idea that deciding whether a task should be exclusive or not shouldn't occur when the task is put on a wait queue, but rather when it is awakened, was developed here at CITI. The process or interrupt that awakens tasks on the wait queue is better able to determine if it wants to awaken one task or all of them. So we eliminated the flag in the task structure* and didn't bother with any special handling in add_wait_queue() or add_wait_queue_exclusive(). With respect to the guidelines above, we felt that the easiest way to implement a solution is to add new calls to complement wake_up() and wake_up_interruptible. These new calls are wake_one() and wake_one_interruptible(). They are #defined macros, just like wake_up() and wake_up_interruptible() and take exactly the same arguments. The only difference is that an extra flag is sent to __wake_up() by these macros, indicating "wake one" as opposed to the default "wake all". This way, it's up to the waker whether it wants to wake one (e.g., to accept a connection) or wake all (e.g., to tell everyone the socket is closed).
For this "wake one" solution we examined the four most often used TCP socket methods and decided which should call wake_up_interruptible() and which should call wake_one_interruptible(). Where we elected to use wake_one_interruptible(), and the method was the default method for all sockets, we created a small function just for TCP to be used instead of the default. We did this so the changes would affect only the TCP code, and not affect any other working socket protocols. If at some point later it is decided that wake_one_interruptible() should be the socket default, then the new TCP specific methods can be eliminated. Based on our interpretation of how each socket method is used, here's what we came up with:
sock->state_change (pointer to tcp_wakeup).............. wake_one_interruptible()
sock->data_ready (pointer to tcp_data_ready).......... wake_one_interruptible()
sock->write_space (pointer to tcp_write_space)......... wake_one_interruptible()
sock->error_report (pointer to sock_def_error_report)... wake_up_interruptible()
Notice that all three of the methods used in accept() call wake_one_interruptible() instead of wake_up_interruptible() when this patch is applied.
* Although, there is a set of flags passed to __wake_up() that emulate the state variable in the task structure, i.e., the flags are set with the same bit masks as those used for the task structure. TASK_EXCLUSIVE is still #defined and passed as a flag to __wake_up() even though it is not used in the task structure.
Benchmark Description
Our focus is on improving system throughput. In this case, we hope to accomplish our goal by eliminating unnecessary kernel state CPU activity. There are two metrics that can be used to determine the goodness of our solution. The first is the amount of time it takes from the initiation of the TCP connection until all tasks are back on the wait queue. The other is purely a measurement of throughput under a high load/stress situation. Therefore, we took two different approaches to benchmarking the performance impact of the "wake one" and "task exclusive" patches. The first is a simple micro-benchmark that is easy to set up and quick to run. We ran this to get an idea of what sort of improvement we were looking at with each patch. The other is a large-scale macro-benchmark on the patched kernels, to see if the patch improves performance under high loads as well.
Micro-Benchmark
This micro-benchmark is a small program we wrote to give some idea of how much time it takes for wait queue activity to settle down after a connection is made. We wrote a small server program that spins X number of threads and has each of them accept on the same port. We also wrote a small client program that creates a socket and connects to the port on the server Y (in this case 1) times. We issue a printk() from the kernel every time a task is put on or removed from the wait queue. After the client "tapped" the server, we examined the output of the printk()'s and identified the point where the connection was first acknowledged (in terms of wait queue activity) and when all tasks finally settled back into the wait queue.
The results are reported as an estimated elapsed time for the wait queue to settle down after an accept() call is processed. The measurements are not exact, as we were using printk()'s and did not take any precautions with regard to concurrency control in doing so. Also, each data point is measured only once as we only need a rough idea of what it looks like. Statistically sound testing is covered in the macro-benchmark. The server was running Linux 2.2.9 on a Dell PowerEdge 6300 with four 450 MHz Pentium II Xeon processors, a 100 Mbps Ethernet card and 512M of RAM (lent to the Linux Scalability Project by Intel).
Macro-Benchmark
To set up the test harness for this benchmark, the Linux Scalability Project purchased four machines for use as clients against the web server. The four machines are equipped with AMD K6-2's running at 400 MHz and a 100 Mbps Ethernet card. The server is the same Dell PowerEdge 6300 used in the micro benchmark. The clients are all connected to the server through a 100 Mbps Ethernet switch. All client machines used in the test harness ran the stock 2.2.9 Linux kernel. The server runs Red Hat Linux 5.2 with a stock 2.2.9 kernel as well as the "task exclusive" and "wake one" patched 2.2.9 kernels.
We elected to use the Apache web server on the server host because it's open source and is easily modified to make this test more useful. Stock Apache 1.3.6 uses a locking system to prevent multiple httpd processes from calling accept() on the same port at the same time, which is intended to reduce errors in production web servers. For our purposes, we want to see how the web serving machine will react when multiple httpd processes all call accept() at once. So we modified Apache so that it doesn't wait to obtain a lock before calling accept(). The file that was changed was (Apache Dir)/src/main/http_main.c. The patch for this file to allow multiple accept calls can be found here.
To stress-test our web server, we used a pre-release version of SPEC's SpecWeb99 benchmark, courtesy of Netscape's web server development team. Because we modified the benchmark's static-dynamic content ratio specifically to hammer the accept() system call (see below), and because the benchmark is pre-release, SPEC rules constrain us from publishing detailed throughput results. However, we are able to report statistically significant throughput improvements.
Running the benchmark establishes n simultaneous connections to the web server from the client machines. Each connection requests a web page and then dies while a new connection is generated to take its place. These runs of the benchmark request only static pages as that will allow it to create more TCP/IP connections per second rather than consuming excess server cycles by running cgi-scripts. This helps generate a higher stress on the accept() system call. The Apache web server starts 1000 HTTP daemons and increases the number if it deems necessary (which it does occasionally due to lingering connections). All of these daemons accept on the same port. The throughput is measured in terms of how many requests per second the n simultaneous connections can make.
Benchmark Results
Micro-Benchmark
| Number of Threads | Unpatched Kernel (us) | Task-exclusive (us) | Wake-one (us) |
|---|---|---|---|
| 100 | 4708 | 649 | 945 |
| 200 | 11283 | 630 | 1138 |
| 300 | 21185 | 891 | 813 |
| 400 | 41210 | 776 | 1126 |
| 500 | 52144 | 567 | 1257 |
| 600 | 75787 | 1044 | 599 |
| 700 | 96134 | 1235 | 707 |
| 800 | 118339 | 1368 | 784 |
| 900 | 149998 | 1567 | 1181 |
| 1000 | 177274 | 1775 | 843 |
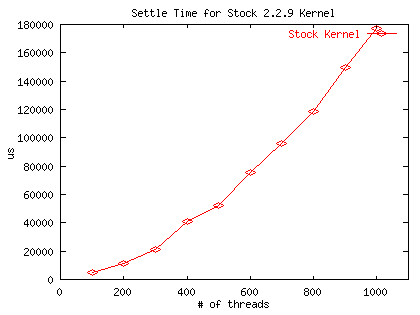
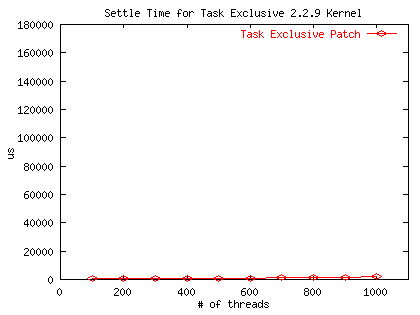
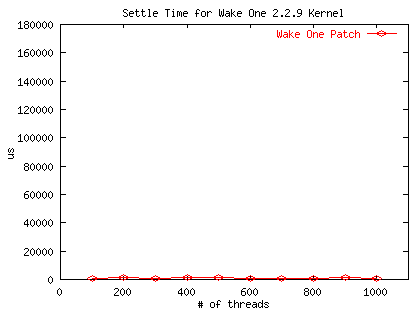
Macro-Benchmark
The results of the macro-benchmark are very encouraging. While running with a stable load of anywhere between 100 and 1500 simultaneous connections to the web server, the number of requests serviced per second increased dramatically with both the "wake one" and "task exclusive" patches. While the performance impact is not as powerful as that evidenced in the micro-benchmark, a considerable gain is evident in the testing. Whether the number of simultaneous connections is at a low level, or reaching the upper bounds of the test, the performance increase due to either patch remains steady at just over 50%. There is no discernable difference between the two patches.
Conclusion
By thoroughly studying this "thundering herd" problem, we have shown that it is indeed a bottleneck in high-load server performance, and that either patch significantly improves the performance of a high-load server. Even though both patches performed well in the testing, the "wake one" patch is cleaner and easier to incorporate into new or existing code. It also has the advantage of not committing a task to "exclusive" status before it is awakened, so extra code doesn't have to be incorporated for special cases to completely empty the wait-queue. The "wake one" patch can also solve any "thundering herd" problems locally, while the "task exclusive" method may require changes in multiple places where the programmer is responsible for making sure that all adjustments are made. This makes the "wake one" solution easily extensible to all parts of the kernel.
References
M Beck, H Bohme, M Dziadzka, U Kunitz, R Magnus, D Verworner, Linux Kernel Internals, 2nd Ed., Addison-Wesley, 1998
Rubini, Alessandro, Linux Device Drivers, O'Reilly & Associates, Inc., 1998
Samuel J Leffler, Marshall K McKusick, Micheal J Karels, The Design and Implementation of the 4.3BSD UNIX Operating System, Addison-Wesley, 1989
Stevens, W Richard, UNIX Network Programming, Volume 1: Networking APIs: Sockets and XTI, 2nd Ed., Prentice-Hall, Inc., 1998
The Single UNIX Specification, Version 2, http://www.opengroup.org/onlinepubs/7908799
Linux Identifier Search, http://lxr.Linux.no/ident
Acknowledgements
Many Linux developers have contributed directly and indirectly to this effort. The authors are particularly grateful for input and contributions from Linus Torvalds and Andrea Arcangeli. Special thanks go to Dr. Charles Antonelli and Professor Gary Tyson for providing hardware used in the test harness for this report.
Availability
The "wake one" patch for accept against the 2.2.9 kernel can be found
here.
The "wake one" patch against the 2.3.12 kernel can be found
here.
The "task exclusive" patch against the 2.2.9 kernel can be found
here.
The "task exclusive" patch has been incorporated into the standard kernel for the 2.3 series.
The patch for Apache's src/main/http_main.c to allow multiple accept calls on the same socket can be found here.
If you have any comments or suggestions, email linux-scalability@citi.umich.edu
|
 |