| |||||||||
|


malloc() Performance in a Multithreaded Linux Environment
Chuck Lever, Netscape Communications Corp.David Boreham, Netscape Communications Corp.
linux-scalability@umich.edu
$Id: malloc.html,v 1.9 1999/11/12 20:12:54 cel Exp $
Abstract |
|---|
| This report describes a simple malloc() benchmark that can drive multithreaded loads in order to test the ability of malloc() to divide its work efficiently among multiple threads and processors. We discuss initial results of the benchmarks, and analyze the results with an eye towards identifying areas of the implementation of malloc() and Linux itself that can be improved. |
|
This document is Copyright © 1999 Netscape Communications Corp., all rights reserved. Trademarked material referenced in this document is copyright by its respective owner. |
Introduction
Many modern network servers use multithreading to take advantage of
I/O concurrency and multiple CPUs.
As network services scale up to tens of thousands of clients per server,
their architecture depends more and more on the ability of the underlying
operating system to support multithreading efficiently, especially in
library routines that are provided not by the applications' designers,
but by the OS.
An example of a heavily-used programming interface that will need to scale well with the number of threads is the memory allocator, known in Unix as malloc(). Malloc() makes use of several important system facilities, including mutex locking and virtual memory page allocation. Thus, analyzing the performance of malloc() in a multithreaded and multi-CPU environment can provide important information about potential system inefficiency. Finding ways to improve the performance of malloc() can benefit the performance of any sophisticated multithreaded application, such as network servers.
This report describes a simple malloc() benchmark that can drive multithreaded loads in order to test the ability of malloc() to divide its work efficiently among multiple threads and processors. We discuss initial results of the benchmarks, and analyze the results with an eye towards identifying areas of the implementation of malloc() and Linux itself that can be improved.
A look at glibc's
malloc()
Most modern distributions of Linux use glibc version 2.0
as their C library.
glibc's implementors have adopted Wolfgang Gloger's
ptmalloc as the glibc implementation of malloc().
ptmalloc has many desirable properties,
including multiple heaps to reduce heap contention
among threads sharing a single C library invocation.
ptmalloc is based on Doug Lea's original implementation of malloc(). Lea's malloc() had several goals, including improving portability, space and time utilization, and adding tunable parameters to control allocation behavior. Lea was also greatly concerned about software re-use, because very often, application developers, frustrated by inappropriate behavior of then extant memory allocators, would write yet another specialized memory allocation scheme rather than re-use one that already existed.
Gloger's update to Lea's original retains these desirable behaviors, and adds multithreading ability and some nice debugging extensions. As the C library is built on most Linux distributions, the debugging extensions and tunability are compiled out, so it is necessary to rebuild the C library, or pre-load a separate version of malloc(), in order to take advantage of these features. ptmalloc also makes use of both mmap() and sbrk() on Linux when allocating arenas. Of course, both of these system calls are essentially the same under the covers, using anonymous maps to provide large pageable areas of virtual memory to processes. Optimizing the allocation of anonymous maps and reducing the overhead of these calls by having malloc() ask for larger chunks at a time are two possible ways of helping performance in this area.
Benchmark description
We've written a simple multithreaded program that invokes
malloc() and free() in a loop, and times
the results.
For a listing of the benchmark program, see Appendix B.
Benchmark data is contained in tables in Appendix C.
The benchmark host is a dual processor 200Mhz Pentium Pro with 128Mb of RAM and an Intel i440FX mainboard. The operating system is Red Hat's 5.1 Linux distribution, which comes with glibc 2.0.6. We replaced the 5.1 distribution's kernel with kernel version 2.2.0-pre4. gettimeofday()'s resolution on this hardware is 2-3 microseconds. During the tests, the machine was at runlevel 5, but was otherwise quiescent.
To measure the effects of multithreading on heap accesses, we'll compare the results of running this program on a single process with the results of two processes running this program on a dual processor, and one process running this test in two threads on a dual processor. This tells us several things:
- How well thread scheduling compares with process scheduling
- How well more than one thread in a process can utilize multiple CPUs
- How well malloc() scales with multiple threads accessing the same library and heaps
- How heavyweight are thread mutexes
We are also interested in the behavior of malloc() and the system on which it's running as we increase the number of threads past the number of physical CPUs present in the system. It is conjectured that the most efficient way to run heavily loaded servers is to keep the ratio of busy threads to physical CPUs as close to 1:1 as possible. We'd like to know what is the penalty as the ratio increases.
For each test, the benchmark makes 10 million balanced malloc() and free() requests. It does this because:
- Increasing the sample size increases the statistical significance of the average results.
- Running the test over a longer time allows elapsed time measurements with greater precision, since short timings are hard to measure precisely.
- Start-up costs (e.g. library initialization) are amortized over a larger number of requests, and thus disappear into the noise.
Specific tests and results
Series One compares the performance of two threads sharing the same C library with the performance of two threads using their own separate instances of the C library. As discussed above, we hope to find out if sharing a C library (and thus "sharing" the heap) scales as well as using separate instances of the C library. On our host, the threaded test did almost as well as the process test, losing only about 10% of elapsed time. We therefore expect malloc() to scale well as the number of threads sharing the same C library increases.For Series Two, we'll be examining the behavior of malloc() as we increase the number of working threads past the number of physical CPUs in the system. We used the same hardware configuration and operating system version for this series as for Series One above. The results are summarized in the following graph:
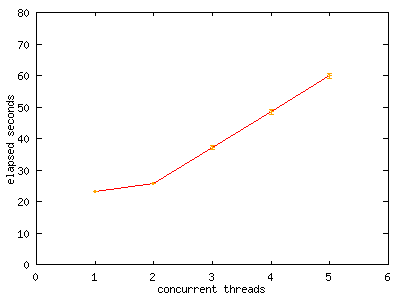
Figure one. Series Two benchmark results
So far, so good: the average elapsed time is increasing linearly with the number of threads, with a constant slope of 1/N * M, where N is the number of processors (N = 2 in our case) and M is the number of seconds for a single thread run (23 seconds in our case).
Now, for fun, let's try something a little more intense. In Series Three, we measure the linearity of the relationship we discovered in Series Two over a much greater number of threads. This will tell us how the library will scale with increasing thread count. The results are summarized in the following graph:
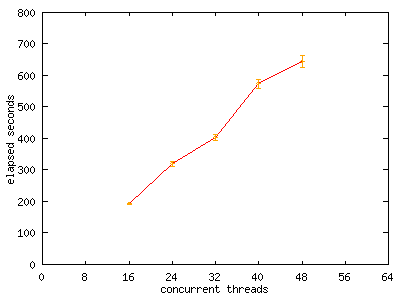
Figure two. Series Three benchmark results
As the graph shows, the increase in elapsed time is fairly linear with increasing thread count, for counts much larger than the number of configured physical CPUs on the system.
Conclusion and Future Work
We are happy to report that, so far,
the malloc() implementation used in glibc 2.0
has effectively handled increasing numbers of threads while
adding little overhead, even for a comparatively large number of
threads.
We found expected performance curves as offered load increased.
In future work, we'd like to compare this implementation of malloc() with a commercial vendor's implementation (for instance, Solaris 2.6 or Solaris 7) in terms of its multithread capabilities. Several quick tries on single and dual processor Ultra 2s show that the Solaris pthread implementation serializes all of the threads created by the malloc-test program. This makes all results we've obtained on Solaris valueless.
Gloger, Wilson, Lea, and others have already spent considerable effort optimizing the basic allocation algorithms. Thus, we believe that another paper measuring these would be a waste of time. However, a close examination of the performance relationship between the C library's memory allocator and OS primitives such as mutexes and sbrk() could have some interesting pay-off. We should also study the effects of allocating in one thread while freeing the same area in another.
Finally, memory allocator performance might benefit from some special knowledge about level-2 cache and main memory characteristics. Page coloring or alignment refinements could help heap storage behave in cache-friendly ways.
Appendix A: Bibliography
- W. Gloger, "Dynamic memory allocator implementations in Linux system libraries", http://www.dent.med.uni-muenchen.de/~wmglo/malloc-slides.html. The ptmalloc implementation can be found at ftp://ftp.dent.med.uni-muenchen.de/pub/wmglo/ptmalloc.tar.gz.
- K. Lai, M. Baker, "A Performance Comparison of UNIX Operating Systems on the Pentium," Proceedings of USENIX Technical Conference, January 1996.
- D. Lea, "A Memory Allocator," unix/mail, December 1996. See also http://g.oswego.edu/dl/html/malloc.html.
- X. Leroy is the author of the Linuxthreads implementation, which can be found at http://pauillac.inria.fr/~xleroy/linuxthreads/.
- C. Staelin, L. McVoy, "lmbench: Portable tools for performance analysis," Proceedings of USENIX Technical Conference, pp. 279-284, January 1996.
- S. Walton, "Linux Threads Frequently Asked Questions (FAQ)," http://metalab.unc.edu/pub/Linux/docs/faqs/Threads-FAQ/html/, January, 1997.
- P. Wilson, M. Johnstone, M. Neely and D. Boles, "Dynamic Storage Allocation: A Survey and Critical Review," Proc. 1995 Int'l Workshop on Memory Management, Springer LNCS, 1995. See also ftp://ftp.cs.utexas.edu/pub/garbage/allocsrv.ps.
- B. Zorn, "Malloc/Free and GC Implementations," http://www.cs.colorado.edu/homes/zorn/public_html/Malloc.html, March 1998.
- B. Zorn and D. Grunwald, "Empirical measurements of six allocation-intensive C programs," Tech. Rep. CU-CS-604-92, University of Colorado at Boulder, Dept. of CS, July 1992.
Appendix B: Benchmark code
/*
* malloc-test
* cel - Thu Jan 7 15:49:16 EST 1999
*
* Benchmark libc's malloc, and check how well it
* can handle malloc requests from multiple threads.
*
* Syntax:
* malloc-test [ size [ iterations [ thread count ]]]
*
*/
#include stdio.h
#include stdlib.h
#include sys/time.h
#include unistd.h
#include pthread.h
#define USECSPERSEC 1000000
#define pthread_attr_default NULL
#define MAX_THREADS 50
void run_test(void);
void * dummy(unsigned);
static unsigned size = 512;
static unsigned iteration_count = 1000000;
int main(int argc, char *argv[])
{
unsigned i;
unsigned thread_count = 1;
pthread_t thread[MAX_THREADS];
/*
* Parse our arguments
*/
switch (argc) {
case 4:
/* size, iteration count, and thread count were specified */
thread_count = atoi(argv[3]);
if (thread_count > MAX_THREADS) thread_count = MAX_THREADS;
case 3:
/* size and iteration count were specified; others default */
iteration_count = atoi(argv[2]);
case 2:
/* size was specified; others default */
size = atoi(argv[1]);
case 1:
/* use default values */
break;
default:
printf("Unrecognized arguments.\n");
exit(1);
}
/*
* Invoke the tests
*/
printf("Starting test...\n");
for (i=1; i<=thread_count; i++)
if (pthread_create(&(thread[i]), pthread_attr_default,
(void *) &run_test, NULL))
printf("failed.\n");
/*
* Wait for tests to finish
*/
for (i=1; i<=thread_count; i++)
pthread_join(thread[i], NULL);
exit(0);
}
void run_test(void)
{
register unsigned int i;
register unsigned request_size = size;
register unsigned total_iterations = iteration_count;
struct timeval start, end, null, elapsed, adjusted;
/*
* Time a null loop. We'll subtract this from the final
* malloc loop results to get a more accurate value.
*/
gettimeofday(&start, NULL);
for (i = 0; i < total_iterations; i++) {
register void * buf;
buf = dummy(i);
buf = dummy(i);
}
gettimeofday(&end, NULL);
null.tv_sec = end.tv_sec - start.tv_sec;
null.tv_usec = end.tv_usec - start.tv_usec;
if (null.tv_usec < 0) {
null.tv_sec--;
null.tv_usec += USECSPERSEC;
}
/*
* Run the real malloc test
*/
gettimeofday(&start, NULL);
for (i = 0; i < total_iterations; i++) {
register void * buf;
buf = malloc(request_size);
free(buf);
}
gettimeofday(&end, NULL);
elapsed.tv_sec = end.tv_sec - start.tv_sec;
elapsed.tv_usec = end.tv_usec - start.tv_usec;
if (elapsed.tv_usec < 0) {
elapsed.tv_sec--;
elapsed.tv_usec += USECSPERSEC;
}
/*
* Adjust elapsed time by null loop time
*/
adjusted.tv_sec = elapsed.tv_sec - null.tv_sec;
adjusted.tv_usec = elapsed.tv_usec - null.tv_usec;
if (adjusted.tv_usec < 0) {
adjusted.tv_sec--;
adjusted.tv_usec += USECSPERSEC;
}
printf("Thread %d adjusted timing: %d.%06d seconds for %d requests"
" of %d bytes.\n", pthread_self(),
adjusted.tv_sec, adjusted.tv_usec, total_iterations,
request_size);
pthread_exit(NULL);
}
void * dummy(unsigned i)
{
return NULL;
}
Appendix C: Raw Benchmark results
Series One
Each table reports elapsed real seconds.
Single process, 10,000,000 requests of 512 bytes each
| Test | seconds |
| 1 | 23.278426 |
| 2 | 23.276260 |
| 3 | 23.289882 |
| 4 | 23.277055 |
| 5 | 23.280160 |
| Average | 23.280357, s=0.005543 |
Two processes, 10,000,000 requests of 512 bytes each
| Test | process 1, seconds | process 2, seconds |
| 1 | 23.316156 | 23.310087 |
| 2 | 23.292935 | 23.330363 |
| 3 | 23.319814 | 23.302842 |
| Average | 23.309635, s=0.014586 | 23.314431, s=0.014267 |
Two threads, 10,000,000 requests of 512 bytes each
| Test | thread 1, seconds | thread 2, seconds |
| 1 | 26.037229 | 26.061006 |
| 2 | 26.054782 | 26.058438 |
| 3 | 26.029145 | 26.070780 |
| Average | 26.040385, s=0.013097 | 26.063408, s=0.006530 |
During this test, top showed that both threads were using between 98% and 99.9% of both CPUs. System (kernel) time was between 0.7% and 1.1% total.
Series Two
One thread, 10,000,000 requests of 8192 bytes
| Test | elapsed seconds |
| 1 | 23.129978 |
| 2 | 23.124513 |
| 3 | 23.123466 |
| 4 | 23.137457 |
| 5 | 23.132442 |
| Average: 23.129571, s=0.005778 |
Two threads, 10,000,000 requests of 8192 bytes each
| Test | thread 1, seconds | thread 2, seconds |
| 1 | 25.831591 | 25.850179 |
| 2 | 25.825378 | 25.827982 |
| 3 | 25.784374 | 25.829218 |
| 4 | 25.786692 | 25.807974 |
| 5 | 25.786227 | 25.808034 |
| Average: 25.813765, s=0.022708 |
Three threads, 10,000,000 requests of 8192 bytes each
| Test | thread 1, seconds | thread 2, seconds | thread 3, seconds |
| 1 | 36.718330 | 36.813648 | 37.948649 |
| 2 | 36.741720 | 37.003884 | 37.804076 |
| 3 | 36.737925 | 36.810934 | 38.019140 |
| 4 | 36.614051 | 36.580804 | 37.983132 |
| 5 | 36.626645 | 36.655177 | 37.966717 |
| Average: 37.134989, s=0.602440 |
Four threads, 10,000,000 requests of 8192 bytes each
| Test | thread 1, seconds | thread 2, seconds | thread 3, seconds | thread 4, seconds |
| 1 | 47.885661 | 47.817898 | 48.158845 | 49.863222 |
| 2 | 47.799143 | 48.086551 | 48.209226 | 49.873930 |
| 3 | 47.653690 | 47.636704 | 48.018065 | 49.970975 |
| 4 | 48.115246 | 48.132953 | 48.316587 | 50.064879 |
| 5 | 48.149170 | 48.315691 | 48.423492 | 49.648395 |
| Average: 48.507016, s=0.844653 |
Five threads, 10,000,000 requests of 8192 bytes each
| Test | thread 1, seconds | thread 2, seconds | thread 3, seconds | thread 4, seconds | thread 5, seconds |
| 1 | 59.294351 | 59.681399 | 59.638248 | 60.130041 | 61.130962 |
| 2 | 59.101132 | 59.284428 | 59.527498 | 59.654372 | 61.693474 |
| 3 | 59.441826 | 59.897381 | 59.666740 | 59.945119 | 61.501687 |
| 4 | 59.222743 | 59.477798 | 59.603993 | 59.459370 | 61.546250 |
| 5 | 59.619357 | 60.110973 | 59.642299 | 59.868556 | 61.076883 |
| Average: 59.968675, s=0.774664 |
Series Three
These tables contain the elapsed time measurements (in seconds) for each thread in a single run.
Sixteen threads, 10,000,000 requests of 4100 bytes each
| 186.847741 | 190.101531 | 189.110768 | 192.143251 | 192.820830 | 193.165536 | 194.002894 | 191.507111 |
| 190.628776 | 192.121089 | 196.755606 | 193.220287 | 192.280556 | 193.925397 | 195.803901 | 193.118177 |
| Average: 192.347091, s=2.427385 |
Twenty-four threads, 10,000,000 requests of 4100 bytes each
| 305.479192 | 306.739658 | 315.626822 | 308.897943 | 314.975798 | 309.208889 | 312.627709 | 314.094961 |
| 324.449772 | 321.174608 | 317.025200 | 317.345414 | 323.886614 | 316.348474 | 325.910042 | 325.329843 |
| 317.232358 | 331.110539 | 331.088659 | 326.364597 | 330.608197 | 327.970896 | 322.656336 | 324.981732 |
| Average: 319.630594, s=7.768588 |
Thirty-two threads, 10,000,000 requests of 4100 bytes each
| 378.857499 | 390.409060 | 396.637062 | 396.073810 | 400.157624 | 405.399191 | 406.583160 | 406.142377 |
| 391.563927 | 395.862463 | 406.918681 | 409.891841 | 400.812766 | 393.261308 | 409.043509 | 401.297264 |
| 401.300762 | 408.055787 | 407.696035 | 413.025337 | 403.367946 | 416.398790 | 400.039313 | 413.406837 |
| 407.783664 | 398.993050 | 411.955450 | 407.682566 | 417.766406 | 410.327972 | 397.859388 | 402.840581 |
| Average: 403.356607, s=8.294892 |
Forty threads, 10,000,000 requests of 4100 bytes each
| 543.494076 | 552.833343 | 550.587209 | 552.684517 | 567.072301 | 573.329704 | 552.832942 | 570.176946 |
| 551.715868 | 559.759884 | 554.505711 | 573.372131 | 586.304418 | 565.601347 | 558.429182 | 569.034294 |
| 574.561367 | 581.152444 | 575.698860 | 576.706009 | 565.202699 | 582.473824 | 588.982964 | 590.090940 |
| 569.908917 | 573.056255 | 591.941499 | 575.474809 | 572.731687 | 595.023077 | 572.121306 | 582.524946 |
| 570.483694 | 597.779803 | 593.384067 | 572.900727 | 590.233710 | 581.866072 | 598.763704 | 591.009196 |
| Average: 573.645162, s=14.495399 |
Forty-eight threads, 10,000,000 requests of 4100 bytes each
| 607.424984 | 626.862756 | 627.084647 | 610.601752 | 610.647375 | 621.802457 | 628.814327 | 623.344699 |
| 636.146533 | 639.063616 | 622.256981 | 628.183262 | 626.409378 | 644.212525 | 639.892038 | 646.027143 |
| 624.227660 | 642.779141 | 646.969559 | 655.019415 | 646.873835 | 653.604088 | 644.001442 | 632.586474 |
| 647.710626 | 633.816685 | 662.139883 | 647.110876 | 661.555068 | 644.822349 | 672.967624 | 670.518977 |
| 664.599045 | 643.017935 | 648.041360 | 644.519162 | 677.222297 | 645.295884 | 654.493092 | 678.516325 |
| 665.871288 | 666.093872 | 657.123928 | 684.276825 | 657.243944 | 664.540376 | 648.818057 | 681.661745 |
| Average: 645.975278, s=18.994390 |
This document was written as part of the Linux Scalability Project. For more information, see our home page.
If you have comments or suggestions, email linux-scalability@citi.umich.edu
|
 |