| |||||||||
|


The primary goal of this research is to improve the scalability and robustness of the Linux operating system to support greater network server workloads more reliably. We are specifically interested in single-system scalability, performance, and reliability of network server infrastructure products running on Linux, such as LDAP directory servers, IMAP electronic mail servers, and web servers, among others.
Summary
We focused on building our web server test harness during the last two months. We've been joined by new staff and new sponsors. We're continuing to reach out to potential sponsors. Work continues on long-term projects.Milestones
- Niels, Peter, and Chuck attended the Usenix Technical Conference in Monterey. Peter and Chuck also attended the Linux Expo in Raleigh, North Carolina.
- Stephen Molloy and Jonathan Nicklin, both U-M undergrads, have joined the project for the summer semester. They are working on porting SpecWeb to Linux and measuring the performance benefits of wake-one accept().
- After a month of working on SpecWeb96, we've obtained a pre-release copy of SpecWeb99, which appears to work more smoothly on Linux. It is capable of providing significantly heavier web server loads than SpecWeb96.
- Sun Microsystems has selected CITI to implement NFSv4 on Linux as part of the IETF standards process for NFSv4. CITI researcher Andy Adamson has joined the project to provide the NFSv4 implementation.
- The contents of the NLnet proposal are still under negotiation. Peter has exchanged lengthy e-mail with NLnet in pursuit of an agreement.
- Almost all legal hurdles have been cleared for the loan of a quad CPU Pentium III to our project.
- We purchased four 400Mhz AMD-K6-II workstations and integrated them into our test harness.
- Stephen Molloy has demonstrated room for improvement in the original wake-one accept() implementation. He is continuing to measure and refine his modifications.
- Chuck eliminated the global kernel lock from the sbrk(), brk(), and mremap() system calls. This will improve the performance of memory-allocation intensive applications on SMP hardware. This patch was included in Linux kernel 2.3.6.
- Chuck produced a kernel hash table analysis report that describes kernel tuning changes that can improve performance from 5% to 10% on large-memory machines. Linux developers decided they'd like dynamically allocated hash tables, so Chuck has produced a patch for the dentry and inode hash tables. The other tables have already been made dynamic due to other kernel improvements.
- Chuck has been working on measuring the performance and scalability impact of holding the global kernel lock during page fault handling. This appears to be a significant expense. The global lock was removed from page fault handling in kernel 2.3.10. We may publish a performance comparison soon.
Challenges
Developer Co-ordination
The current structure of the Linux kernel community is an evolved system of geographically scattered developers who are tied together by an e-mail list, an anonymous CVS server for some non-Intel platforms, and a handful of ftp and web sites.While there are vague assignments of areas of expertise, there appears to be no public co-ordination of who is doing what and when. This leads to some frustration in the greater kernel development community, because often duplicated effort results, and it appears that some work is favored over other work for no apparent reason. As one .sig states,
There is something frustrating about the quality and speed of Linux development, ie., the quality is too high and the speed is too high, in other words, I can implement this XXXX feature, but I bet someone else has already done so and is just about to release their patch.
For instance, the Linux Scalability Project was founded to focus on improving SMP scalability, among other specific issues. During the past two months, many of the SMP scalability issues in the Linux kernel have been directly addressed by a few Linux developers. The areas that have been addressed so far include threading the networking stack and the page cache, two areas that are critical for scalably providing enterprise-class networking service on SMP hardware.
Because of these issues, the Linux Scalability Project, which originally thought it would concentrate on providing patches, is adapting to a new role within the Linux community. We carefully measure, and then point to areas that may be improved. Sometimes we may provide a fix, but often the community of developers is better equipped to find and fix a performance or scalability problem once it has been identified.
Integrated kernel debugging tools
It is a stated philosophy of the Linux community that there shall be no integrated kernel debugging tools. The high reliability of Linux is often attributed to the lack of traditional debugging tools commonly available to other software projects. The defect rate of Linux is remarkable considering there are few debugging tools available. However, the reason it is so low is more likely because the lack of debugging tools prevents people from getting involved and fixing problems, so only the experts can fix problems. Preventing a flood of fixes and modifications helps keep the change rate lower (ostensibly a good thing), and limits the amount of parallel work that can proceed on the kernel.Moreover, attributing the high quality of fixes to lack of debugging tools does a disservice to the level of expertise of those working on Linux, and to Linus' ability to recognize and apply a good fix when he sees it. It would be hard for anyone to break out a single reason why Linux bug fixes are the way they are.
It should be stated that the one of the main advantages of GPL-style open-source development projects is that there will never be a bar to becoming involved in such a project. New developers can join open mailing lists and participate immediately with seasoned hackers. But because Linux is a volunteer effort, it must face the risks inherent in having developers with widely varied skill levels working on it. Thus, limiting changes to the kernel has a stabilizing effect, and keeps the risk of damage done by donated code at a minimum. However, even if non-experts aren't allowed to submit code to the Linux kernel, they should still be allowed to hack on their own kernels, and they should have the tools to do this expediently.
One of Linux's success stories is the kernel source code review process. It's not perfect, but it does contribute significantly to the overall consistency of the kernel, moreso than I think the availability and style of debugging tools does. Not having debugging tools also means that some code is not as well tested, because the existing testing methodologies are intrusive and painful (that is, printk's in the kernel). Even though Linux doesn't have lots of unnecessary checks for NULL pointers, for instance, the problems and bugs that do exist seem to languish for a very long time, often cropping up later after significant changes happen to the kernel.
It's been pointed out that there are several interesting interactive kernel debugging tools available to the Linux community, including kdb developed by an SGI software engineer, and the IKD patch maintained by Andrea Archangeli. These are great tools. The problem is that before they can be useful, the developer community must wait for them to become available for the kernel revision they are debugging. Neither IKD nor kdb are ported to the 2.3 series kernels at the moment. I can envision one of these patches integrated into the mainstream kernel and enabled/disabled via compile-time CONFIG. To clarify, I recognize that interactive kernel debugging tools are available, but just not "integrated" as well as they could be.
I'm really interested in two things: improving the quality of information in bugs reported by non-kernel developers, and helping people solve their own problems. Improving bug report quality can only help those who actually do have control over what goes into the kernel distribution. And empowering individuals to solve their own problems is what open source software is all about, isn't it? Both Solaris and AIX, traditionally delivered in binary-only form, have some good ideas to offer here. They've had to develop good tools because their users/customers receive their product in binary-only form.
In conclusion, I believe that anything that controls the rate of change is a good idea. I'd like the change management to be more direct and considered than artificial and arbitrary, though, and it seems like leaving out debugging tools is an artificial throttle on positive changes. For example, more folks could be providing fixes and new features of quality if there were integrated debugging tools and a stronger, more consistent review process. Although, I do realize there is a practical limit on Linus' time to handle a stream of reviewed fixes/features.
In other words, if what you're trying to accomplish is:
- change control
- long meaningful learning curves for new hackers
- weeding out ill-designed new features
then you should state it overtly rather than sneak it in by leaving out the tools to help developers do their jobs. I basically agree with the ends, but not the means.
Performance graphs
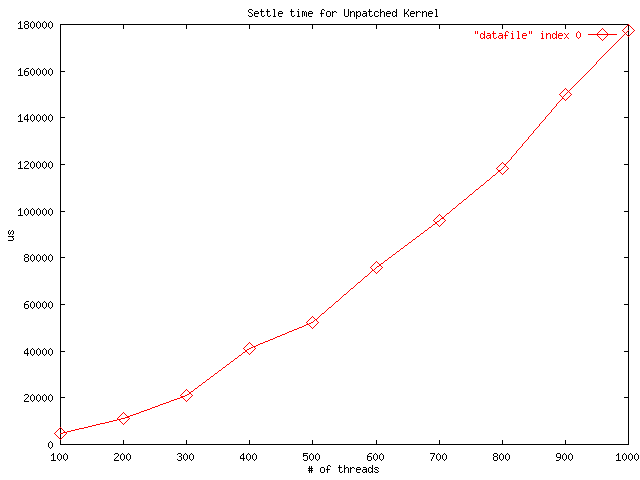
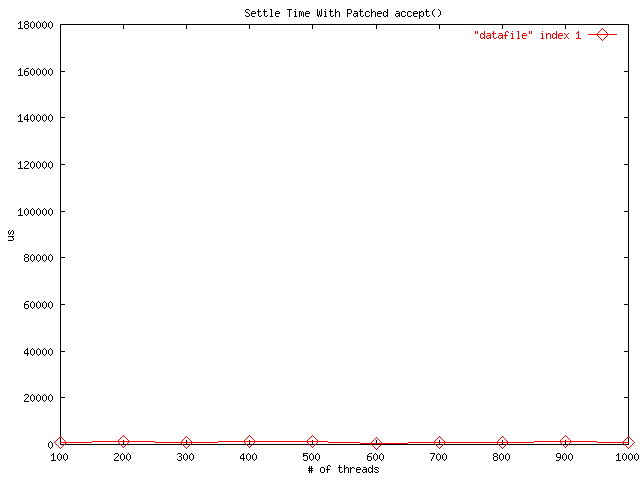
These graphs measure the amount of elapsed wall time required for an accept() operation in kernel 2.2.9, and the time required with our patched version of accept(). X-axis units are number of threads waiting in accept(), and Y-axis units are microseconds. This microbenchmark was run on a Dell PowerEdge 6300 with four 450Mhz Xeon processors and 512M of RAM.
If you have comments or suggestions, email linux-scalability @ citi.umich.edu
|
 |