| |||||||||
|


Purpose
I am investigating the behavior of the congestion control mechanism in Linux's RPC layer. In order to gain a basic understanding, it is interesting to observe NFS behavior with congestion control removed.
Chuck Lever observed that when congestion control is removed, there are periodic spikes in the latency of write operations. You can view his expirement here. As a follow up, I ran a write test with and without congestion control, and observed the OTW (on the wire) latencies of the individual RPC write commands.
Procedure
The write test performed is test5a from the Sun Connectathon Suite. This test performs a sequential write to a file of a specified size. I used a 160 MB file.
In order to observe the OTW behaviour, I captured the network activity with tcpdump. I then used ethereal to print a text summary, and wrote a perl script to pull the interesting data out of that summary. One problem with this method is that some packets are dropped by the kernel, and not recorded with tcpdump.
The latencies I measured are found by subtracting the time stamp of a server's reply from the timestamp of the original command. In the case of retransmitted commands, I used the most recent transmission for this calculation.
I also recorded retransmissions, and how long the client waited to retransmit.
Graph Interpretation
For latency points, the x coordinate is the time at which the server's reply was received. The y coordinate is the time between the command being sent, and the reply being received.
For retransmission points, the x coordinate is the time at which the client retransmitted the command. The y coordinate is the time between the retransmission, and the previous transmission.
For example, consider the following trace:
| 0 ms | send | xid 1 |
| 1 ms | send | xid 2 |
| 5 ms | receive | xid 2 |
| 700 ms | re-send | xid 1 |
| 703 ms | receive | xid 1 |
In this example, there are two RPC commands, with xid's 1 and 2. The first RPC is sent at 0 ms, re-sent at 700 ms, and finally acknowledged at 703 ms. This would give a latency of 3 ms, and the latency point (701 ms, 3 ms). It also gives the retransmit point (700 ms, 700 ms).
The second RPC gives the latency point (5 ms, 4 ms)
Baseline Measurements
I first performed the test with a stock 2.4.4 kernel. Here are the overall results:
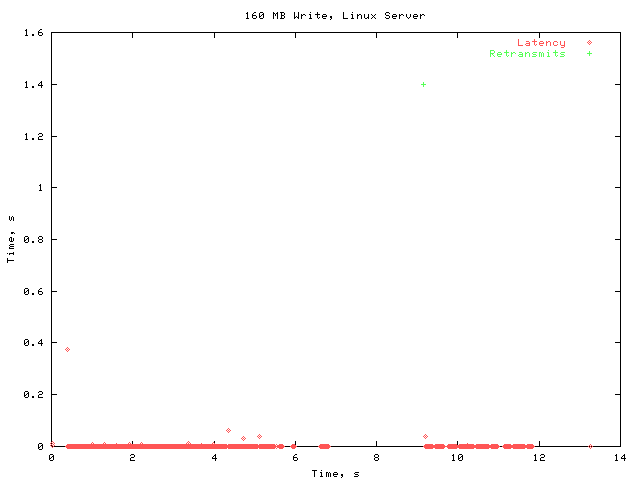
The latency is generally quite low. Notice the large gap in the vicinity of 8 s. This is caused by RPC packets that timed out. For these tests, the default timeout value of 700 ms was used. At the end of this timeout interval, the dropped packets are retransmitted.
Here is the same graph, with a smaller y scale, to get a better look at the common case latencies.
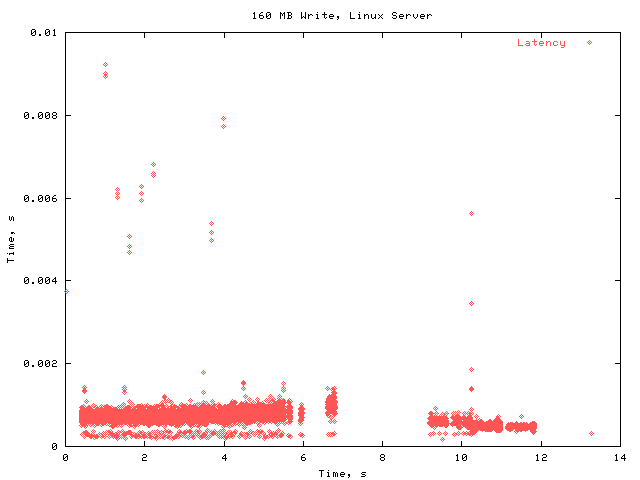
The OTW latency is generally under 1 ms, with some occasional small spikes.
Measurements With No Congestion Control
Congestion control was removed from the kernel by editing xprt_reserve_status in net/sunrpc/xprt.c to not check the current congestion value. I then performed the same 160 MB write test.
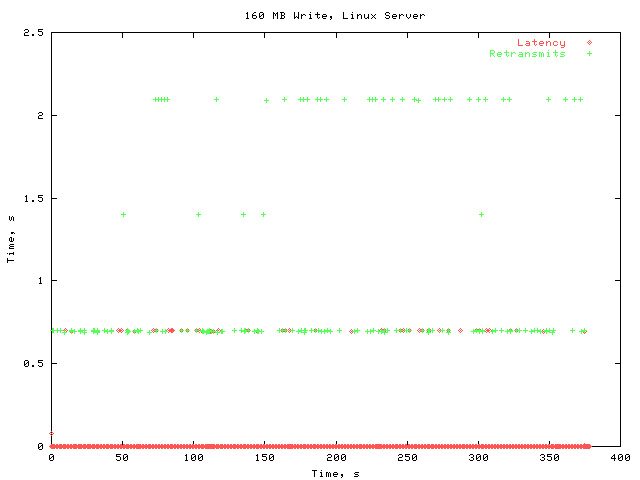
The latency here is generally still very low. However, there a lot of retransmissions here. Overall, the performance is quite poor; the total write operation took about 375 s, as opposed to about 12 s in the stock kernel.
Notice that some of the latency points lie on one of the horizontal lines associated with retransmissions. I believe that these points may be fallacious. As I mentioned earlier, tcpdump does not record all of the packets. I believe that in these cases, the retransmission was missed by tcpdump, causing the apparent latency to be roughly the time between the two transmissions.
In order to compare the behavior over time to that of the stock kernel, here is the same graph with the same x scale used in the baseline measurement.
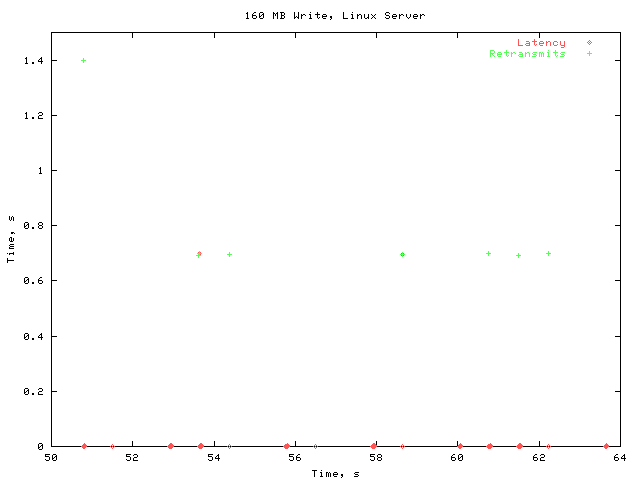
Here you can see that timeouts are occurring regularly, causing an enormous performance penalty.
Here is the same data with the full x scale, but a small y scale so that we can see the latency values more clearly.
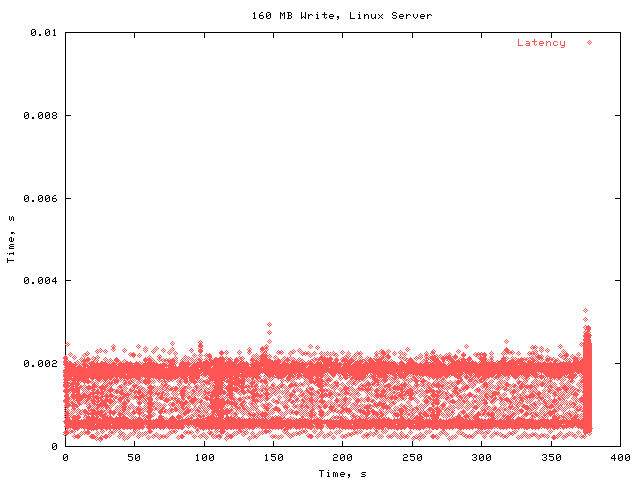
The latencies here are only moderately higher than in the stock kernel.
Follow-Up Testing
After performing these tests, I investigated further to find the cause of the timeouts. I put some printk statements in the kernel of the nfs server, and found that almost all of the timeouts were caused by the server dropping the UDP packets. Specifically, the socket's receive buffer would fill up, forcing the server to drop incoming packets.
The other lost RPCs occurred when the NFS server code dropped the RPC.
I then looked at the rate the client sends RPCs. In the stock kernel, they were issued at a steady 3500 RPCs/s. With an 8k write size, this is about 28 MB/s
Without congestion control, the RPCs were issued in bursts. I measured two of these spikes. One was 6700 RPC/s (54 MB/s), and the other was 12000 RPC/s (98 MB/s). However, between timeouts, the average rate was only 3100 RPCs/s (25 MB/s).
Conclusions
Without congestion control, the linux client sends RPCs in bursts. In our testing, this caused the server to drop UDP packets. On a WAN, the results would probably be even worse, as any intermediate points between the client and server will be likely to drop packets.
In any modifications to the RPC congestion control mechanism, it will be important to suppress sending bursts of RPCs. When spaced evenly, the server and intermediate points will be less likely to have to drop packets.
|
 |