| |||||||||
|


Further Analysis of a 2000 MB write to an F85 File Server
When I showed my previous results with the F85 Filer Server to my coworkers, they suggested I try using a RAID volume with more disks in it. The volume I used for my first test had 2 disks; adding more disks would improve disk throughput, and may solve the problems I was seeing before.
The following test was done a volume consisting of 6 disks. Using this larger RAID array solved the problems I saw with the filer in my first test.
Overall Picture
Here is the overall picture of the 2 GB write.
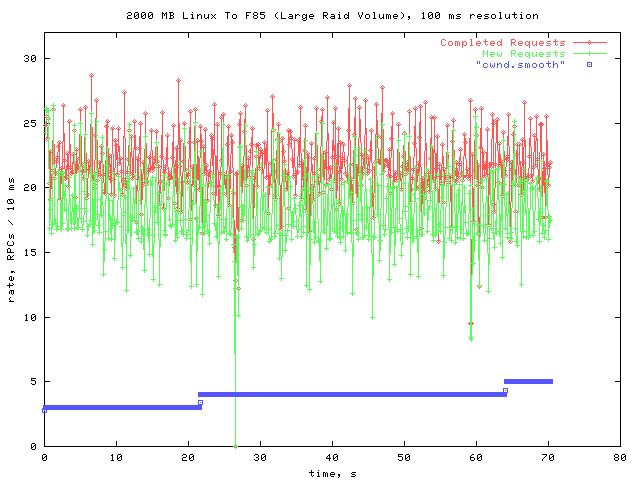
The graph now looks more like my results with the Linux NFS server. There are no timeouts, and only one noticeable gap. The total time taken is now significantly less than for the Linux server.
I performed a second write test to see if the cwnd would continue to climb, or if a timeout would occur.
Second 2000 MB Write
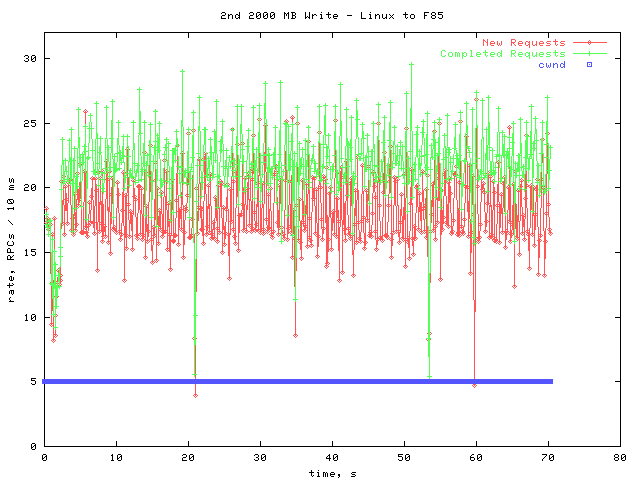
No timeouts occurred, and the cwnd remained steady. Apparently, the total time taken for the test was less than the time necessary to raise the cwnd again.
The only oddity in this graph is the low rates for the first few seconds.
A Closer Look
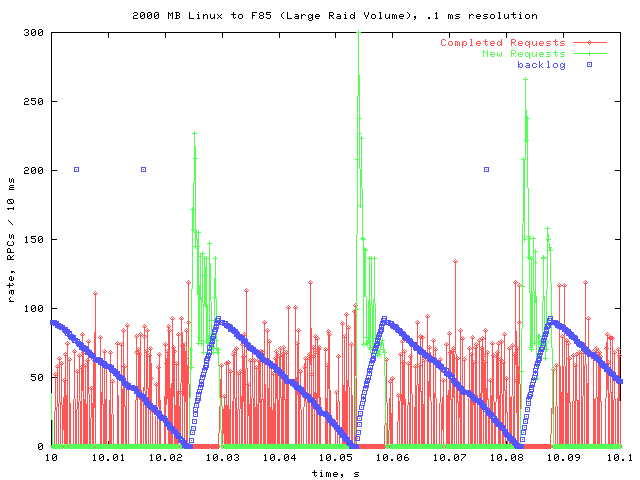
There is nothing particularly new about this graph. It is virtually identical to the corresponding graphs from the first two tests I did. However, I went back and measured how long the drain cycles took in each test. For BOTH of the tests against the Filer, a typical cycle took roughly 24 ms. For the NFS server, a typical cycle took roughly 30 ms. The lower time for the Filer is at least partially due to its NVRAM, which allows it to tell the client that the data is committed without actually writing it to disk right away.
Now that the problems caused by the poor performance of the 2 disk RAID volume have been eliminated, the Filer's faster response time allows it to outperform the NFS server.
Gap
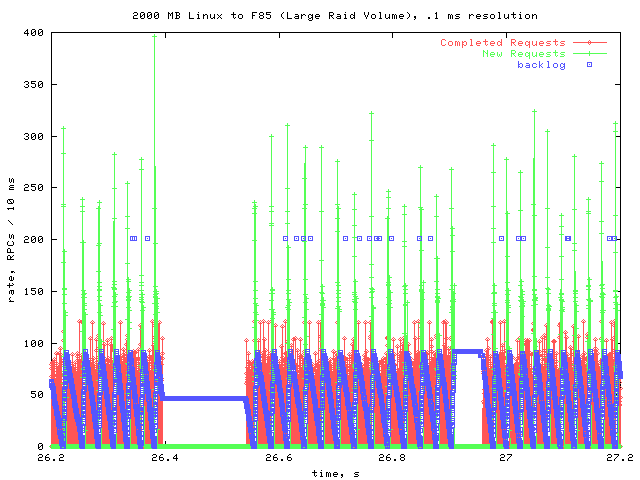
This is a closeup of the one time that the throughputs fell to zero in the overall graph. It seems to have involved two stalls.
Here is a lower resolution graph of the same data, with the pending queue shown:
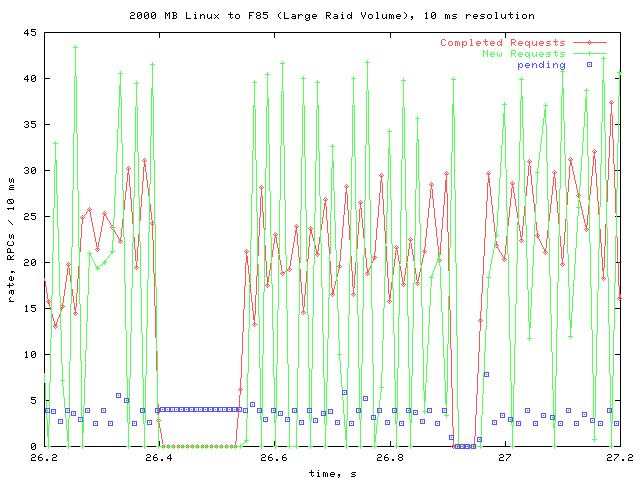
The first stall has some pending requests, while the second stall has none. The second stall is probably due to the client stopping to do something else, while the first stall could be the same thing, or the server stalling. Either way, it isn't of much concern, as it didn't occur significantly through the tests.
Slow Section
Here is a closer look at part of the first, slow, part of the second transfer.
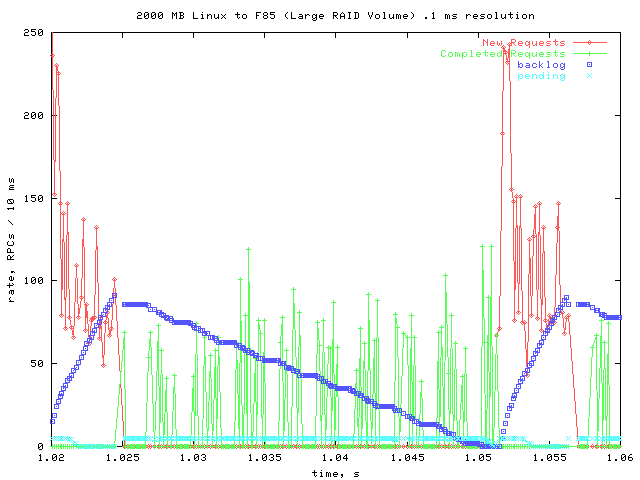
There are many small gaps in this section, leading to overall poor throughput. The pending queue is full during all of the gaps, leading me to believe that it is the server that's stalling.
Conclusions
Using the larger RAID array fixed the problems that I was experiencing before with the Filer. It now performs quite well.
I still have the following questions about the RPC layer that I would like to answer.
- Why aren't any requests being completed when new requests are coming in? This may be a side effect of my rpcstat tool using one of the cpus, but this needs to be verified. UPDATE: Further testing has shown this to be due to the intrusive nature of the rpcstat test. This effect doesn't happen in my latest version of the tool, which yields the processor more often.
- Why does a timeout stop everything for ~1.5 seconds? This seems excessive, although it isn't as much of an issue now that fewer timeouts are occurring.
- What are the variations at the beginning of the tests? The F85 sometimes performed poorly at the beginning of a test. The Linux server tended to do better at the beginning of a test. These effects could have an impact on performance when working with many small files rather than one large one.
- Is processing in the RPC layer a bottleneck?
|
 |